Since I last wrote about it, Technology Operations (TechOps for short) has evolved. Particularly Development Operations, or DevOps for short, has become widely adopted + continues to evolve, coupled with new technologies that have been directly influenced by it + the culture it has helped shape. Even though many organizations are still struggling to realise the potential of DevOps due to a lack of expertise +/or cultural challenges, it’s already indisputably been a mainstream improvement, a movement away from how we used to build + deliver products and services into the world to a better way of working together.
As a result, traditional hardware platforms, the hypervisors + virtual machines of yesterday are giving over to serverless architectures + other, more efficient and cost-effective strategies for managing all of the complexity of the hidden machinery behind apps, websites + other data-driven products. Will this continued shift lead to even better overall collaboration?
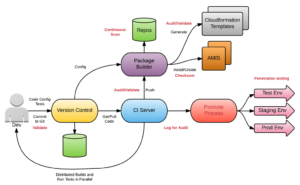
 Collaboration
Collaboration
Deploying even the most simple functions in these environments naturally requires crucial decisions across disciplines, including development, operations, security + financial. At a minimum, decisions such as the amount of available memory + timeout (the time budget for the function invocation) influence cost. Beyond these even, the team has to decide who/what has access, through what means/protocols and for how long, setting expectations about the lifespan for the function – how long will it be viable + useful?
These decisions all factor into the modern-day pay-for-what-you-use cost structures that are based on memory usage + the time it will be used to execute said function, which is, in turn, also linked to the underlying platform the function is running on (if running in a container or more traditional platform, like a computing instance). Whatever the case, memory is like fuel. Burn more fuel, burn more processing power, burn more throughput, burn more money. The team all needs to chime in on the burn rate.
With cost effectiveness riding on optimal configurations of these architectures, it’s crucial to adjust settings based on a balance of budget vs. required performance. If you’re thinking, “Why does it always have to be a tradeoff?” you’re spot on. That’s where metrics come in.
Measurement
There are more useful tools than ever for providing insight into the performance of infrastructure + they are essential to operating these architectures because, without them, costs are more difficult to contain than more traditional, less flexible + soon-to-be-obsolete architectures. Using them well, however, makes these next-gen architectures faster to provision, more scalable + secure, higher performing + more cost effective, especially because metrics are available from the moment resources are provisioned, unlike their predecessors, where it often takes weeks, sometimes months, before all the tooling is in place.
There is another upside to this, too, including insight into more operational considerations, such as capacity planning, performance monitoring + logging. This is more opportunity for the team to collaborate as more information on their work becomes available in short order.
 DevSecOps
DevSecOps
Better security, anyone? Better business continuity? Traditionally, security + resilience in software delivery was addressed as an afterthought, if at all. While serverless architectures provide environment parity, which increases consistency + predictability in the workloads of developers, ops + security, by extension this consistency + predictability also facilitates better security.
Unikernel architectures, for example, eliminate overhead as stripped down stacks, free from burdensome operating system bloat to minimize the attack surface for those so inclined to try to exploit it.
Considerable complexities are built into the Linux kernel to keep users safe from other users, but also to keep apps safe from users + other apps. That means a lot of added complexity, such as permission checks, remnants from an era when it was necessary on larger systems to delineate + segregate all the apps + users all working on the same hardware.
This complexity means the Linux kernel has a larger attack surface than is always necessary. Historically, to minimize this risk, operations teams would patch the kernel, potentially creating compatibility issues with development teams who are writing code on the platform. Tracking interactions between the two teams is a painful + tedious process that creates issues, such as outages + worse. It’s hard to fix the car while we are driving it.
 These new building blocks, containerized, eliminate these challenges, offer more powerful automation capabilities to create immutable infrastructure. In a containerized environment, security problems aren’t handled by modifying something that is already running. Instead, whole new containers are deployed because images are already vetted, which means the chances of introducing bugs, compatibility issues + flaws into production are radically minimized. Even trying to install malicious code in a containerized environment only means it will be destroyed when images are updated.
These new building blocks, containerized, eliminate these challenges, offer more powerful automation capabilities to create immutable infrastructure. In a containerized environment, security problems aren’t handled by modifying something that is already running. Instead, whole new containers are deployed because images are already vetted, which means the chances of introducing bugs, compatibility issues + flaws into production are radically minimized. Even trying to install malicious code in a containerized environment only means it will be destroyed when images are updated.
This means that security is solved pro-actively, as functions are deployed, rather than reactively because each function has an associated security policy, the right security policy for the function based on its job, based on the principle of least privilege. For example, functions that only need to query a specific database table only requires permissions to query that one thing + nothing else.
It’s self-evident that serverless models are making security more a part of the development process rather than deferring until operations teams get involved when it’s typically too late to address uncovered issues easily or properly. This shift in culture has given rise to DevSecOps principles.
These great new principles? They look something like this:
- Customer-focused (internal, too, not just external)
- Scalability (obstacles to deployment are removed while still achieving compliance)
- Objective criteria (what’s best for the collective vs. one team or discipline)
- Pro-active hunting vs. reactive responding (the new architecture allows for this)
- Continuous detection and response (pro-active vs. reactive)
Three cheers for DevSecOps.
More Adaptable Environments
Being able to spin up as many environments as needed, whenever they’re needed, offers exciting new possibilities. What if each member of the dev team has their own environment in the cloud? Maybe each feature being developed is deployed into a dedicated environment so it can be demoed independently without any impact to the larger system as a whole. These separate environments can even live on separate providers, creating a degree of segregation that’s only been imagined, until now.
 Rise of the Generalists
Rise of the Generalists
Broad skillsets + good familiarity with cloud platforms can achieve more + do it much quicker than specialized skillsets locked into a single, more traditional method of working. Many development + operational activities can be integrated into cycles + costly handoffs to segmented internal or external resources can be eliminated altogether.
Ideally, the whole team should participate in delivering a feature, including operating it in production. This is the best way to make sure the team is incentivised to produce quality software operable from go. I’ve shared thoughts on distributed work approaches + agile ad nauseam.
Old Challenges, New Outcomes
While many companies are still talking about bringing dev + ops closer together, still struggling to establish some form of DevOps culture + practice, their efforts will be bolstered by this latest shift. The serverless approach offers a new strategy for creating a culture of rapid business value delivery + operational stability, while offering new strategies for containing costs +, the best part, uniting teams better than in the past. Serverless workflows are the embodiment of DevOps cultures, where technologies, methods + tools are forged to be ready for production right from the start, with nods to each discipline involved. No small thing.
 New Challenges, New Outcomes
New Challenges, New Outcomes
While it’s true that only a few organizations are mature enough in their current DevOps cultures to welcome the brave new world of serverless right away, + while it is also true that these ways of working are indeed brave + still immature, they offer the organizations that have fallen behind a chance to cover lost ground quickly. Doing so requires a lot of work to identify, define + address the new challenges it presents to each, unique culture, but will be worthwhile for new + improved outcomes.
The most common challenge to overcome? Organizations open + willing to build a serverless practice may do so using their already existing processes + structures, losing any speed they could have gained. It is key to realize this change in its entirety. Not a small task.
Even when done right, those companies who are able to succeed will most likely have to go back to the front + redefine not only the way they deliver products + services but also the way they sell them. Is this a good problem to have, though? Definitely.
Summary
The next iterations of operations cultures will include better integration of security culture, serverless architectures + workflows that are designed, out-of-the-box, for rapid delivery of business value. Continuous improvement + learning have clear potential, such as the rise of DevSecOps in earnest, to further elevate the cultural shift that began with DevOps, even in organizations that are working towards achieving it.
This is good news, too, for those less technically inclined as these tools + processes are much more user friendly than anything that’s come before them. Training all kinds of people to be fluent in these tools will be easier as there is much less complexity coupled to much more computing power + better protections for privacy + security.
Good things ahead.